新出论文总结
本文档主要记录新出的论文(包括大量ArXiv预印本),主要是学习思路和方法,其具体水平还有待时间检验。
目录
| 简称 | 发表信息 | 核心贡献描述 | 具体信息 | 传感器 | 其他 |
|---|---|---|---|---|---|
| RobMOT+ | ArXiv 2025.5 | 提出动态调整运动模型的思路 | 查看 | 3D+2D | |
| DIMM | ArXiv 2025.5 | IMM改进,强化学习计算转换矩阵,各个方向进行拆分 | 查看 | 3D(未提到传感器) |
论文详情
TOWARDS ACCURATE STATE ESTIMATION: KALMAN FILTER INCORPORATING MOTION DYNAMICS FOR 3D MULTI-OBJECT TRACKING {#RobMOT+}
- 发表信息: ArXiv 2025.5
- 未开源
核心贡献描述
说是动态模型,不如说是动态调整模型的参数。作者首先使用一个基座运动模型:Jerk模型(一直建模到加加速度)。然后给速度,加速度,加加速度一个权重,通过调整权重来实现模型的动态调整。 而权重的获得,理想情况下是通过目标真实运动状态的差分(及高级差分)获得的。但是真实状态不可得,作者使用去噪的观测值来近似真实状态,从而计算出差分。此外,并非简单差分就是权重,还设置了一个高斯分布,以及归一化来获得权重。
学习收获
作者的运动模型,实质上就是CV,CA,JERK。但是没有考虑到转向模型。不过思路可以借鉴学习,也就是通过后续的真值来动态调整运动模型。 对比作者的上一篇工作,提升真的不高。
DIMM: Decoupled Multi-hierarchy Kalman Filter for 3D Object Tracking
- 发表信息: ArXiv 2025.5
- 未开源
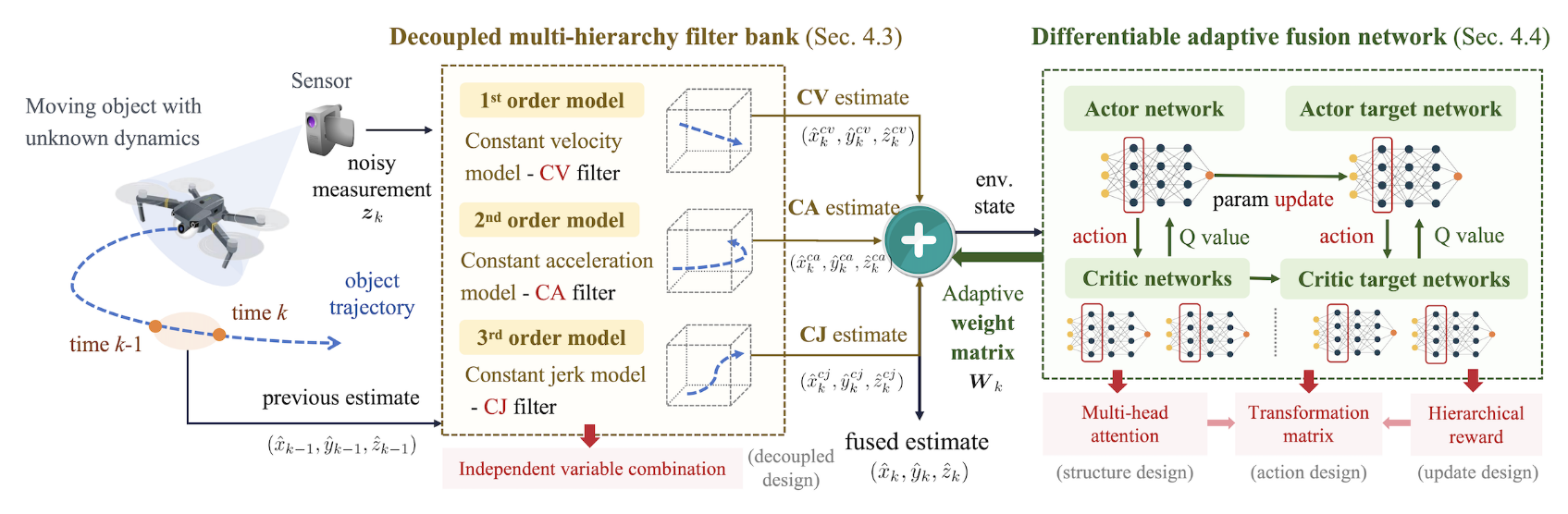
核心贡献描述
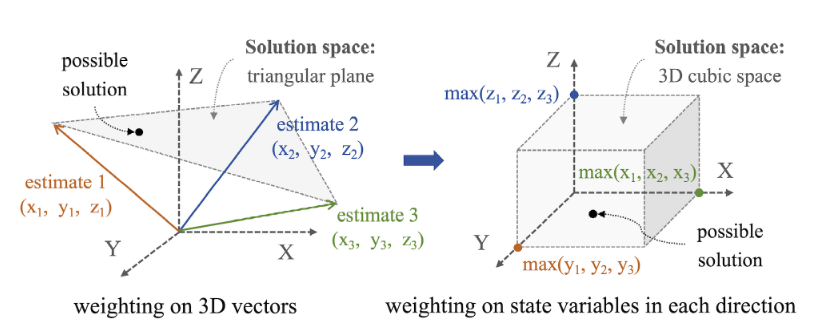
主要提出了两个大的创新点。首先作者的baseline是IMM(交互多模型滤波器)。它指出IMM存在的两个大问题:首先是3维各个方向的运动状态可能是不相同的,而IMM是把各个方向的状态耦合在一起的。其次,IMM在更新模型概率时,是用的观测的值作为真值来计算误差,从而更新概率,这里就引入了观测噪声的问题。 针对第一个问题,作者提出了将3维各个方向的状态进行拆分。每个维度上分别做CV,CA,CK模型的IMM。作者提到这样做扩大了解的空间。但是我认为这个说法有一定的问题。假如说三个模型的状态向量不存在平行,那么他们就是三维空间的一组基向量,一样是可以表示任意的三维状态的。而拆分成基坐标系,就相当于把基向量换成了标准正交基而已。但是,我也同意作者的部分观点:这样确实扩大了解的空间:由于固定模型,所以状态向量的变化范围是受限的,而拆分后,每个维度的状态向量可以独立变化,从而扩大了状态向量的变化范围。这个部分我觉得还可以更进一步,沿着作者的思路走:各个方向上的运动是不一样的。
针对第二个问题,作者提出了使用强化学习的方法来学习生成概率矩阵。 其中值得借鉴的是奖励的设置。不同于将和真值的误差作为奖励,作者将“模型的误差”和”普通IMM的误差“之间的差值作为奖励。这样缓解了观测噪声的问题。当学习模型比传统方法好的时候,奖励为正,否则为负。
学习收获
- 各个方向运动不同。拆分的方法可以试试效果先。
- 学习奖励的设计。
模板
- 发表信息:
- 未开源