新出论文总结
本文档主要记录新出的论文(包括大量ArXiv预印本),主要是学习思路和方法,其具体水平还有待时间检验。
目录
| 简称 | 发表信息 | 核心贡献描述 | 具体信息 | 传感器 | 其他 |
|---|---|---|---|---|---|
| RobMOT+ | ArXiv 2025.5 | 提出动态调整运动模型的思路 | 查看 | 3D+2D | KITTI |
| DIMM | ArXiv 2025.5 | IMM改进,强化学习计算转换矩阵,各个方向进行拆分 | 查看 | 3D | 强化学习 |
| MLA-MOT | TITS2026 | 多级关联+质量感知轨迹修正,系统解决预测/关联/漂移三大问题 | 查看 | LiDAR | KITTI |
| EMMS-MOT | RA-L2024 | 多模态位置协调+扩展KF联合观测,提升3D运动建模精度 | 查看 | LiDAR+camera | NuScenes/KITTI |
| GroupTrack | IROS2024 | 引入群组运动先验辅助遮挡目标预测,仅IoU关联即达SOTA | 查看 | camera | MOT17/20 |
| PB-MOT | IROS2025 | 旋转椭圆IoU兼顾效率与精度,自车运动解耦改善关联 | 查看 | LiDAR | KITTI |
| PD-SORT | TCE2025 | 伪深度作为2D MOT第三运动维度,提升遮挡鲁棒性 | 查看 | camera | DanceTrack/MOT17/20 |
论文详情
TOWARDS ACCURATE STATE ESTIMATION: KALMAN FILTER INCORPORATING MOTION DYNAMICS FOR 3D MULTI-OBJECT TRACKING {#RobMOT+}
- 发表信息: ArXiv 2025.5
- 未开源
核心贡献描述
说是动态模型,不如说是动态调整模型的参数。作者首先使用一个基座运动模型:Jerk模型(一直建模到加加速度)。然后给速度,加速度,加加速度一个权重,通过调整权重来实现模型的动态调整。 而权重的获得,理想情况下是通过目标真实运动状态的差分(及高级差分)获得的。但是真实状态不可得,作者使用去噪的观测值来近似真实状态,从而计算出差分。此外,并非简单差分就是权重,还设置了一个高斯分布,以及归一化来获得权重。
学习收获
作者的运动模型,实质上就是CV,CA,JERK。但是没有考虑到转向模型。不过思路可以借鉴学习,也就是通过后续的真值来动态调整运动模型。 对比作者的上一篇工作,提升真的不高。
DIMM: Decoupled Multi-hierarchy Kalman Filter for 3D Object Tracking
- 发表信息: ArXiv 2025.5
- 未开源
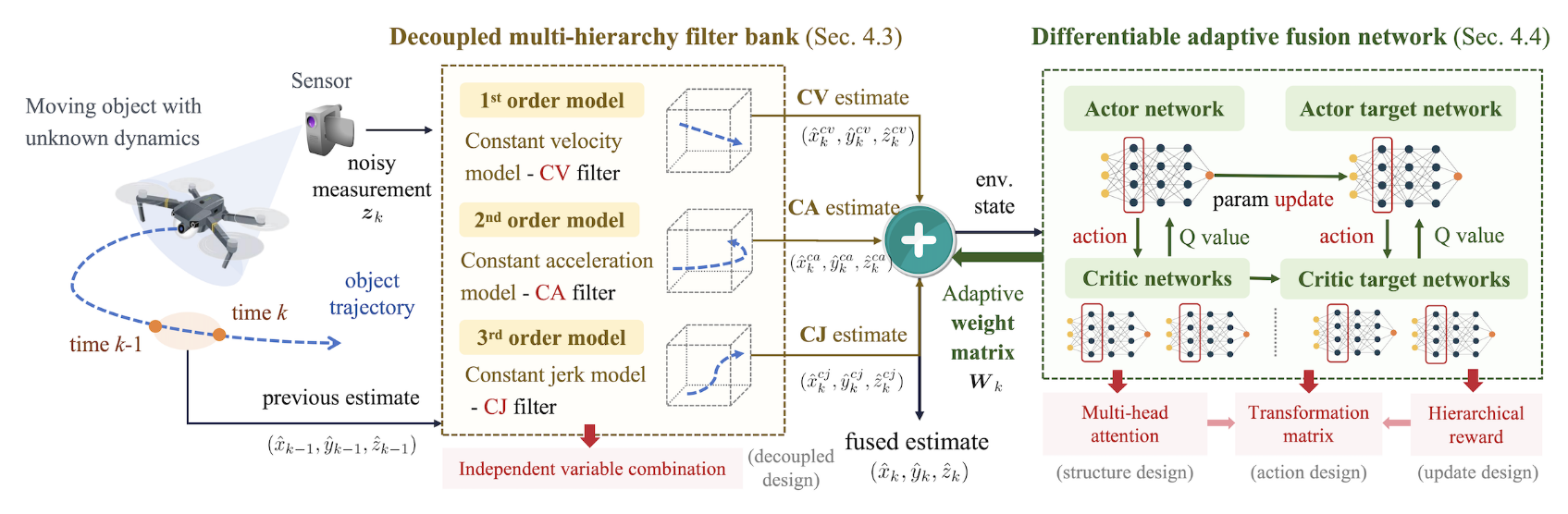
核心贡献描述
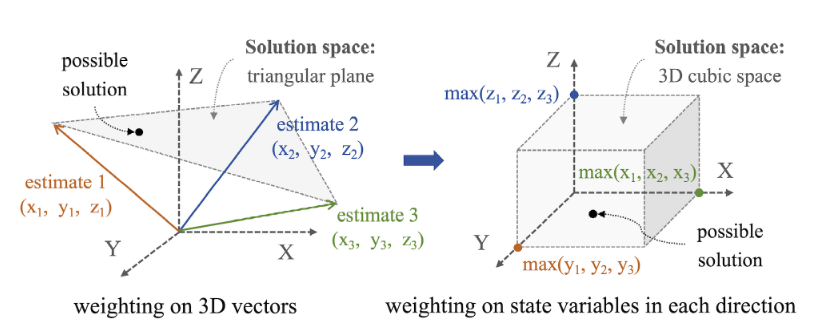
主要提出了两个大的创新点。首先作者的baseline是IMM(交互多模型滤波器)。它指出IMM存在的两个大问题:首先是3维各个方向的运动状态可能是不相同的,而IMM是把各个方向的状态耦合在一起的。其次,IMM在更新模型概率时,是用的观测的值作为真值来计算误差,从而更新概率,这里就引入了观测噪声的问题。 针对第一个问题,作者提出了将3维各个方向的状态进行拆分。每个维度上分别做CV,CA,CK模型的IMM。作者提到这样做扩大了解的空间。但是我认为这个说法有一定的问题。假如说三个模型的状态向量不存在平行,那么他们就是三维空间的一组基向量,一样是可以表示任意的三维状态的。而拆分成基坐标系,就相当于把基向量换成了标准正交基而已。但是,我也同意作者的部分观点:这样确实扩大了解的空间:由于固定模型,所以状态向量的变化范围是受限的,而拆分后,每个维度的状态向量可以独立变化,从而扩大了状态向量的变化范围。这个部分我觉得还可以更进一步,沿着作者的思路走:各个方向上的运动是不一样的。
针对第二个问题,作者提出了使用强化学习的方法来学习生成概率矩阵。 其中值得借鉴的是奖励的设置。不同于将和真值的误差作为奖励,作者将“模型的误差”和”普通IMM的误差“之间的差值作为奖励。这样缓解了观测噪声的问题。当学习模型比传统方法好的时候,奖励为正,否则为负。
学习收获
- 各个方向运动不同。拆分的方法可以试试效果先。
- 学习奖励的设计。
3D Multi-Object Tracking Driven by Multi-Level Association and Intelligent Filtering
- 发表信息: IEEE TITS, Vol.27 No.1, January 2026
- 未开源
核心贡献描述
针对3D MOT中预测、关联、修正三个环节的缺陷,提出三个配套模块形成闭环:
AESSP(自适应估计平滑状态预测):用加速度差分动态估计下一时刻加速度:$\hat{a}^j_{t+1} = \xi a^j_t - a^j_{t-1}$,再用平滑因子融合预测速度与估计速度,抑制预测噪声。本质仍是线性外推,但比纯CV/CA更贴近真实运动。
MLTIA(多级轨迹集成引导关联):按检测和轨迹的置信度各分高/低两类,进行4级级联匹配(高×高用3D IoU,低×高用3D GIoU,依此类推)。轨迹置信度由KF协方差矩阵量化,遮挡目标复现时的置信度变化规律也作为辅助相似度。
QIFTC(质量感知智能滤波轨迹修正):计算检测框与轨迹预测方向的角度偏差 θ,超过阈值则判定为漂移检测,对中心坐标、尺寸、朝向角分别用指数衰减函数回归修正,再送入KF更新,避免误差积累。
学习收获
- 多级关联的思路本质是ByteTrack的扩展,但以置信度双维度划分(检测+轨迹)比单维更细致,遮挡轨迹的处理更系统。
- QIFTC的角度偏差检测漂移的思路值得借鉴:用预测方向和观测方向的一致性作为质量信号,比纯置信度更能感知几何异常。
- 行人类HOTA仅53%,说明方法对尺寸小、运动随机的目标泛化性弱,主要价值在车辆跟踪。超参数多(C、ω、α、β、τ),工程成本不低。
Exploiting Multi-Modal Synergies for Enhancing 3D Multi-Object Tracking
- 发表信息: IEEE Robotics and Automation Letters, Vol.9 No.10, October 2024
- 未开源
核心贡献描述
指出现有多模态方法(EagerMOT、DeepFusionMOT)只是简单拼接两模态检测结果,未利用2D与3D之间的空间协同和运动协同关系,提出三个模块:
MMLC(多模态位置协调器):对同时被两个模态检测到的目标,求解最小化2D投影误差与3D中心误差加权和的优化问题,用牛顿法迭代修正3D中心坐标,权重由检测置信度经sigmoid自适应计算。
MMME(多模态运动估计器):将扩展卡尔曼滤波的观测向量同时纳入3D坐标和2D像素坐标 $(u,v)$,通过相机投影关系联系3D状态,用2D观测补偿3D空间线性假设的误差。
MSDA(多阶段数据关联):三轮匈牙利匹配,代价矩阵融合3D GIoU和2D GIoU,分别处理双模态检测、纯3D检测、纯2D检测三种情况。
NuScenes测试集:AMOTA 76.4%,IDs降至271(-21 vs PolyMOT)。整体无需额外训练(learning-free)。
学习收获
- 核心思路:让2D观测帮助修正3D状态,在EKF框架内扩展观测向量,是比简单拼接更深层的融合。MMME对ID下降的贡献最大,说明运动建模质量比关联规则更根本。
- MMLC只修正3D中心,不修正朝向和尺寸,修正不完整;依赖精确内外参,工程部署受限。
- 假设z轴高度恒定、xy均匀加速,对起伏路面失效,NuScenes复杂场景提升幅度相对保守。
GroupTrack: Multi-Object Tracking by Using Group Motion Patterns
- 发表信息: IROS 2024, Abu Dhabi
- 未开源
核心贡献描述
密集人群中相邻行人运动模式高度相似,提出利用这一先验——用高质量邻居轨迹的运动推断遮挡目标的位置,替代直接用低质量检测更新KF。
邻居选择:联合标准化欧氏距离(SEC,以目标宽度归一化隐含深度)和速度余弦距离(VCD,过滤方向差异大的轨迹),同时满足时序相关性阈值的轨迹成为邻居。
群组运动模式推断(GMP):对低质量轨迹,用邻居当前速度估计其位置:
$$L^j_{low} = \tilde{T}^c_{low} + (\tilde{T}^v_{low} - \tilde{T}^v_j) + T^v_j$$加权平均所有邻居的推断结果(权重为运动相似度),得到"推断框"参与关联和KF更新。
数据关联仅用IoU,两轮匈牙利匹配。MOT17:HOTA 65.2%,IDs 1161(vs ByteTrack 2196),IDs减少约一半。
学习收获
- 群体运动先验是被长期低估的方向。核心观察朴素但有效:行人聚集时运动高度相关,遮挡目标的位置可由邻居"代为估计",不需要外观模型也能大幅减少ID错误。
- 仅用IoU关联仍达SOTA,说明运动建模质量的提升才是根本,而非关联函数的复杂化。
- 速度突变(起步、急停)时邻居估计会引入额外误差;全场大规模遮挡时可用邻居减少,性能退化风险大。未来可结合速度置信度自适应关闭GMP。
PB-MOT: Pose-aware Association Boosted Online 3D Multi-Object Tracking
- 发表信息: IROS 2025, Hangzhou
- 未开源
核心贡献描述
3D MOT关联面临复杂性-精度困境:IoU精度高但计算重,距离类方法快但忽略朝向。同时自车运动与目标运动耦合导致KF预测偏差。提出四个模块:
旋转椭圆IoU(RE-IOU):以旋转椭圆等高线建模目标框,等高线形状由长宽比 γ 和速度自适应旋转角 θ_rot 控制,用**切比雪夫多项式(4阶)**近似三角函数大幅降低计算复杂度,最终精度接近GIoU,速度接近欧氏距离。
扩展代价函数:在RE-IOU基础上乘入朝向代价 $\mathcal{O}$(检测与预测朝向余弦差)和存在代价 $\mathcal{E}$(轨迹历史关联成功率),同时加权双阈值重标定后的检测置信度。
自车运动解耦(EM):从SLAM/GPS获取帧间自车相对位姿变换,将前帧轨迹转换到当前坐标系,再用CV+KF预测目标绝对运动。
自适应轨迹管理(ATM):区分静止目标和运动目标,静止目标采用更慢的存在代价衰减,避免遮挡时被错误删除。
KITTI在线方法:HOTA 81.94%,AssA 85.55%,MOTA 91.32%,CPU速度 2402.76 FPS。
学习收获
- RE-IOU是本文最实质的贡献:兼顾效率和精度,切比雪夫近似的工程创意值得学习,HOTA vs GIoU提升+1.265%证明其有效。
- 自车运动解耦在动态驾驶场景中必要性高,FRAG减少31.85%是直接证明。静止/运动目标分类管理轨迹寿命的思路也值得参考。
- 2402 FPS仅含跟踪算法本身(不含3D检测器),实际系统参考价值有限;依赖SLAM/GPS在室内或GPS遮挡区域失效。旋转椭圆在朝向接近0°/90°时等高线形状与真实框吻合度下降。
PD-SORT: Occlusion-Robust Multi-Object Tracking Using Pseudo-Depth Cues
- 发表信息: IEEE Transactions on Consumer Electronics, Vol.71 No.1, February 2025
- 代码公开
核心贡献描述
2D MOT遮挡场景下,目标边界框重叠导致纯位置信息无法区分不同目标,提出将伪深度作为第三运动维度引入KF状态:
伪深度建模:通过"补充视角"无需深度传感器估计伪深度:$pd = 2 \times IMG_h - Y_b$(图像高度两倍减去框底部y坐标),对目标移出边缘的情况鲁棒。将 $pd$ 和深度速度 $v_{pd}$ 加入KF状态向量。
深度体积IoU(DVIoU):将2D IoU扩展为体积IoU,引入伪深度作为第三维:$V = w \cdot h \cdot pd$,遮挡时2D重叠但深度不同的目标可被有效区分。
量化伪深度测量(QPDM):将帧内深度范围等分为若干区间,用区间编号代替原始深度值,减少部分遮挡引起的深度估计误差传播。
相机运动补偿(CMC):稀疏光流+RANSAC估计仿射变换,校正运动相机引起的位置偏移,同时修正KF状态和历史观测坐标。
DanceTrack:HOTA 58.2%(+3.6 vs OC-SORT),AssA 42.1%(+1.9),IDF1 57.5%(+2.9)。
学习收获
- 核心思路有意义:在纯2D场景中将深度信息引入运动状态是首次尝试,无需深度传感器。DanceTrack +3.6 HOTA证明在外观高度相似+非线性运动+密集遮挡场景下深度线索确实有效。
- DVIoU混合了像素坐标和伪深度量纲,物理意义上不严格,需精细调参;伪深度核心假设(相机在地面以上、目标在同一地平面)在坡道、楼梯或大俯仰角相机下失效。
- MOT17/20提升仅+0.6~0.7 vs DanceTrack的+3.6,说明方法价值集中在非线性运动+遮挡的特定场景,行人直线行走场景提升有限。
模板
- 发表信息:
- 未开源