
Harness-Engineering
Harness-Engineering
Harness-Engineering 是AI时代中出现的一种新型软件开发流程。
Humans steer. Agents execute.
关键发展
2025.11.26,Anthropic在其官方博客上发布了名为“Effective harnesses for long-running agents”的文章,探讨了有效使用AGENT的关键因素。这是比较早开始探讨Harness的文章之一。但是这一概念真正受到广泛关注是由openai公司的“零代码实验”引发的。
2026.2.11,OpenAI在其官方博客上发布了名为“Harness engineering: leveraging Codex in an agent-first world”的文章。文中作者介绍了他们过去5个月的探索:构建并发布一个内部测试版的软件产品,代码全由AI完成。由此,这一概念引起了广泛关注,认为可能是AI时代的软件开发新范式。许多知名博主也纷纷发表了相关评论和分析文章。
2026.2.17,知名博主发表了名为“Harness Engineering”的文章,进一步分析了OpenAI的这一探索,并提出了自己的见解。
Harness engineering: leveraging Codex in an agent-first world
openai的这一实验,软件开发中的:应用逻辑、测试、CI配置、文档、可观察性和内部工具(application logic, tests, CI configuration, documentation, observability, and internal tooling)全部是由AI完成的,没有人敲过一行代码。
该项目真正被Openai内部(数百名用户)使用。5个月的实验,代码的规模达到了百万行,大约有1500个PR,但是只有3名工程师参与。研究员估算,用时约为传统开发的1/10。
他们怎么做的?
2025.8月,他们正式开始这个实验,创建了这个空的git仓库。
然后由codex cli(gpt-5)搭建了最初的工程骨架(CI 配置,代码规范,依赖管理,应用框架),其中参考了一些现有的模板。
然后团队开始项目推进,起初他们的进展比预期慢,因为他们发现AGENT缺少能够达到高目标要求所需的 工具,抽象和内部结构(tools, abstractions, and internal structure).
为了解决这个问题,他们首先开始往深挖:将大目标拆解成小的模块,让AGENT能够构建这些模块,进而可以实现更大的目标。
工程师描述任务,运行AGENT,并允许他们打开一个PR。提交一个PR之前,工程师会要求codex在本地审查变更,还有其他特定的AGENT审查本地和云端的变更。codex根据人类以及其他AGENT的反馈进行迭代,直到PR被所有审核员批准(Ralph Wiggum Loop)。
其中,codex会使用一些工具:gh(GitHub CLI工具),本地脚本,仓库内置能力(repository-embedded skills)等来获取上下文,完成工作。
工程师可以审核PR,但是非必须,到后期审核也是由AGENT完成。
提高代码可读性
AGENT敲代码速度比人快太多了,很快就能敲出一大陀,人工审核可能都跟不上。软件开发的瓶颈逐渐就变成了人工质量控制的能力(human QA capacity)
显然,让AGENT能够自己处理才是更好的解决方案。所以,openai的工程师的工作就是给AGENT开发了一套工具,让他们能够更好的观察现有的情况。
首先,他们让每个AGENT工作在一个独立的git worktree中。
关于前端开发,他们将 chorme-devtools 接入到AGENT中,使得能够处理DOM快照,截图和导航等。所以可以重现漏洞,验证修复,推理UI行为。
关于观测工具,他们构建了这样一个系统。针对每个worktree,会建立一个观测堆栈,存放着日志、指标,错误跟踪(Logs, metrics, and traces)等。当这个任务完成后,这些内容会被删除。
而AGENT访问这些内容则是:用LogQL查询日志,用PromQL查询指标。
有了这些工具的加持,AGENT就能够完成:“确保服务启动在800毫秒内完成”,“这四个关键用户旅程(从操作到完成)的耗时均不得超过两秒”这种任务。
openai分享的两个流程
- 涉及UI相关
- 确定目标+清空console面板
- snapshot BEFORE
- 触发UI交互
- snapshot AFTER
- 开始修改,从头再开始
- loop
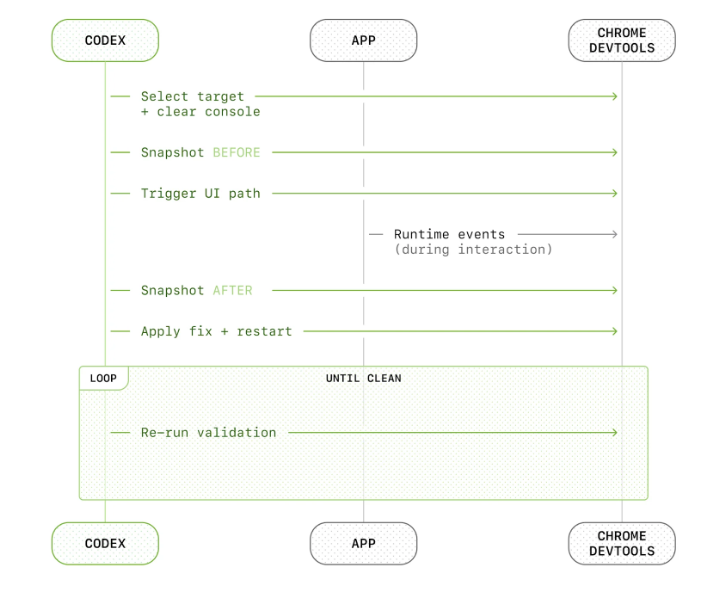
- 完整的可观测流程
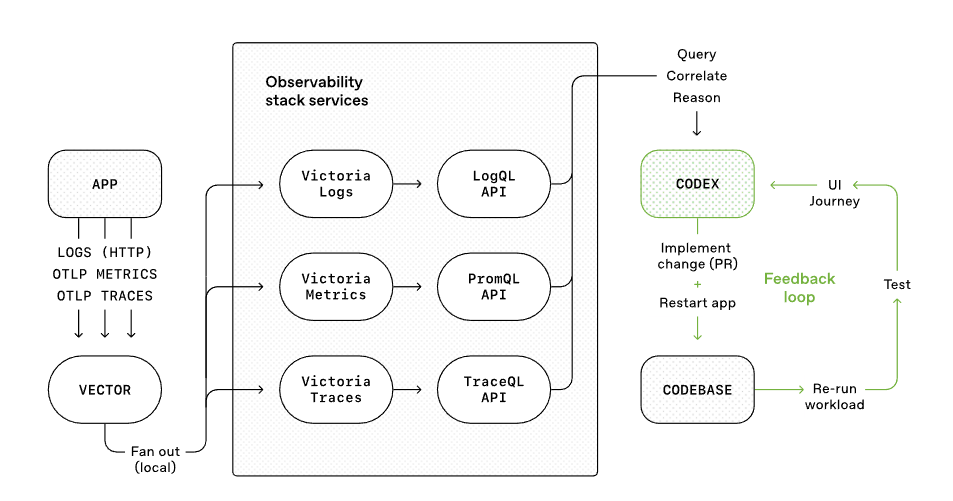
APP通过OpenTelemetry (OTLP) 协议原生输出三类可观测数据:日志、指标和跟踪数据。
接着这些数据由数据代理层(VECTOR)处理,将数据可靠地路由转发到后端的可观测性栈服务中,起到缓冲、转发和初步处理的作用。
然后就是核心的可观测性栈服务(OBSERVABILITY STACK)
日志体系,对外通过 LogQL API 提供查询能力(LogQL 是类似 PromQL 的日志查询语言)
指标体系,对外通过 PromQL API 提供查询能力
链路体系,对外通过 TraceQL API 提供查询能力(用于筛选和分析具体的调用链路)
这些作为后端的可观测性服务,提供相应观测反馈。最后再结合例子1中的前端流程,形成了整个软件开发的闭环。
其他经验分享
前面说的是如何让 AGENT 来管理审查流程,要让 AGENT 能够更好自主完成工作,还需要让 AGENT 能够更好的理解任务,选择合理的实现方向。
- 使用更朴素的技术路线
从代理的角度来看,任何它们运行时无法访问的内容都等于没有。(例如,聊天群组中的讨论,谷歌文档等)。也就是说,AGENT需要不断的添加上下文并迭代,就像一个新员工需要了解产品原则、工程规范和团队文化一样。
因此,这就需要实现的方法更容易内化并推理。也就是说,AGENT 软件开发青睐的技术路线是那种“保守,平淡”的技术路线,它们组合性强、API 稳定,且在模型训练数据中覆盖面更广。 - 自己造轮子
在部分场景下,让智能体自行重新实现部分功能子集,反而比迁就公共库黑盒化的上游行为成本更低。
总得来说,就是要让系统实现成__智能体可直接查阅、校验、修改的形态__。
上下文管理
这是一个大型项目中绕不开的挑战。
首先他们否定了一种方法:复杂的AGENT.md文件。理由如下:
- 语境是稀缺的:庞大的指令文件挤压了任务、代码和相关文档——所以代理要么遗漏关键约束,要么开始针对错误的约束进行优化。
- 过度指导等于没有指导:当一切都“重要”时,什么都不重要。
- 会很快的失效:人类停止维护,变成巨大的麻烦。
- 很难进行验证:覆盖率、时效性、归属权、交叉关联校验等
他们提出了一个新的思路。不把AGENT.md当作一个百科全书,而是把它当作一个目录。
具体的实现是,仓库的知识库存储在一个结构化的docs/目录中,一段简短的AGENTS.md(大约100行)被注入语境中,主要作为地图,指向更深层的信息。
1 | # 具体文件结构 |
这些文件具体的内容如下:
- 设计文档(Design documentation):有统一编目和索引的设计文档。需要注意的是,这些文档中,还包括:某个模块的验证状态,‘AGENT First’的核心设计理念。
- 架构文档(Architecture documentation):提供各业务域与软件包分层的顶层视图
- 质量文档:对每个产品域和架构层进行评级,并持续跟踪长期存在的能力缺口。
- 计划文档(Plan):临时性的轻量规划用于小型变更,而复杂工作则会记录在执行规划中,附带进度日志与决策日志,并提交至代码仓库。活跃规划、已完成规划以及已知技术债务均进行版本化管理并统一存放,使智能体无需依赖外部上下文即可运行。
通过这样的结构化文档,AGENT能够从一个精简且稳定的入口点开始,逐步学习后续的信息,避免一次接收导致过载。
要确保这套规范能够顺利实施(包括AGENT遵守以及文档的维护),openai通过自动化手段强制执行上述规范。专用的代码检查工具(linter)与持续集成任务会验证知识库是否保持最新、交叉引用是否完整、结构是否规范。一个定期运行的 “文档治理” 智能体会扫描与实际代码行为不符的陈旧或废弃文档,并自动发起修复类拉取请求。
一致性(Enforcing architecture and taste)
仅靠文档,是无法维持生成的代码库整体逻辑一致。必须要通过__强制约束不变量__、而非微观管控具体实现细节,让智能体能够快速交付迭代,同时不破坏项目底层根基。
例如,openai让 AGENT 在系统边界层完成数据结构解析校验。
这个需求(强制约束)也带来了新的设计方向:系统需要具有严格边界和可预测结构。也就是说,每个业务域被划分为固定的层,具有严格验证的依赖方向和有限的允许边集。这些约束通过自定义linters和结构测试机械性地强制执行。
具体来说,在每个业务域(例如「应用设置」)内部,代码仅允许单向向前依赖,严格遵循固定分层顺序:类型定义 → 配置层 → 数据仓储层 → 业务服务层 → 运行时层 → 界面层。
跨领域通用能力(鉴权、外部连接器、可观测性遥测、功能灰度开关)统一通过唯一的显性抽象入口 ——Providers(供应器) 接入。
除此之外的所有非法依赖方式都被禁止,并通过自动化机制强制校验拦截。
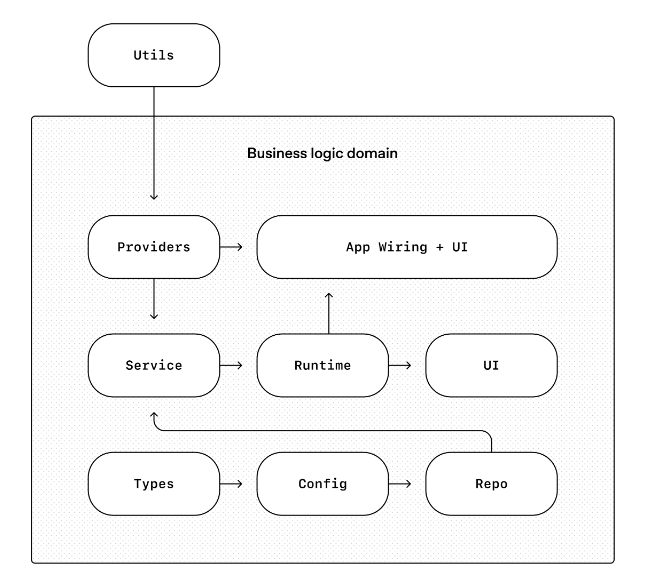
这种框架,对于过去的开发方式,可能需要团队规模到几百人才会使用。但在AGENT时代,这种框架却是必需的:正是这些刚性约束,才能让研发保持高速迭代,同时避免系统腐化与架构跑偏。
除开架构约束,具体的实现时,也需要进行约束。例如,通过自定义代码检查器(Linters)、结构校验测试,以及一些个性化要求来强制落实这些架构规则。
例如要求,静态强制实现结构化日志、数据模式与类型的命名规范、文件大小限制,以及特定平台的可靠性要求。
并且,由于linter自研,特意将错误提示信息编写成可直接供智能体执行的修复指令。
这些实现,体现出重要的思想:集中管控边界,局部下放自治。高度重视系统边界、代码正确性与可复现性,在边界内则允许智能体自由发挥,快速迭代。
这样的规则和约束,最终生成的代码也许不符合人类的审美,但是此时我们的评价标准已经发生了改变:只要输出正确、可维护、对AGENT可读就行。
整个流程中,人类的品味(审美)不断反向沉淀到系统的规则和约束中。评审意见、重构类合并请求,以及面向用户的线上问题,都会被整理为文档更新,或是直接固化到工程工具链中。一旦文档约束力度不足,我们就会把对应的规则升级,写入代码与自动化校验逻辑里强制执行。
宽松的CI流程
随着 AGENT构建速度的增加,许多传统工程规范变得适得其反。
例如,传统的CI流程中,只要有一个测试失败了,整个流程就会被阻塞,无法继续进行。
对于 AGENT 来说,如果一个测试是偶尔失败的,它再跑一次CI成功后,就允许合并。
为什么?因为AI写代码太快了,比review速度快多了。如果依然等待,那么就会成为瓶颈,阻碍迭代速度。
因此,openai决定用适当放宽的CI流程来换取更快的迭代速度。(corrections are cheap, and waiting is expensive)
Redefining the role of the engineer
前面说到,这个项目中,没有一行人写的代码。那工程师干啥?
openai的答案是:一种更侧重于系统构建,基础支撑的搭建,构造放大效能杠杆(focused on systems, scaffolding, and leverage)的工作。
AGENT 将负责完成:
- 生成代码和测试 Product code and tests
- CI配置和发布工具 CI configuration and release tooling
- 开发内部工具 Internal developer tools
- 文档和设计 Documentation and design history
- 评估 Evaluation harnesses
- 查看评论和反馈 Review comments and responses
- 管理仓库脚本 Scripts that manage the repository itself
- 生成控制台定义文件 Production dashboard definition files
人类工程师始终参与,但工作层次发生了变化。编排工作,将用户的反馈转换为验收标准,验收AGENT的输出。当AGENT遇到困难的时候,我们去寻找现在缺什么(工具、约束护栏、文档规范),然后告诉 AGENT 让他们去构建这些东西。
越来越多的开发环节被 AGENT 接管,使得它们拥有了端到端的处理能力。
当然,这样的方法也有新的问题。AGENT 采用的不可能是最均衡/最优的开发模式,随着时间推移,不可避免会产生漂移。
openai最开始是花费大量时间,人工兜底,清理 AI垃圾, 很明显是不可持续的。
他们思路就是,维护一个“黄金规则” 以及 搭建了一个周期性的代码清理机制。
规则带有明确技术倾向、可机器强制执行的标准化规则,用以确保代码库清晰可读、风格统一,便于后续智能体持续迭代开发。
例如:优先使用公共通用工具包,而非零散手写工具方法,以此集中统一管控全局不变量;杜绝「盲目硬写」式数据探测:必须在校验系统边界,或依托强类型 SDK 进行开发,防止智能体依靠猜测的数据结构盲目编写业务逻辑。
整体来说,这种方式就像高利贷:持续小额分批偿还,永远好过任由利息复利累积,最后集中爆发、痛苦集中还债。
最后,我们回到我们的目标:构建并维护复杂且可靠的大型软件。我们的挑战是设计环境、反馈循环和控制系统,以让 AGENT 搞笑实现我们的目标。